|
|
|
| Document Creation: Overview |
|
|
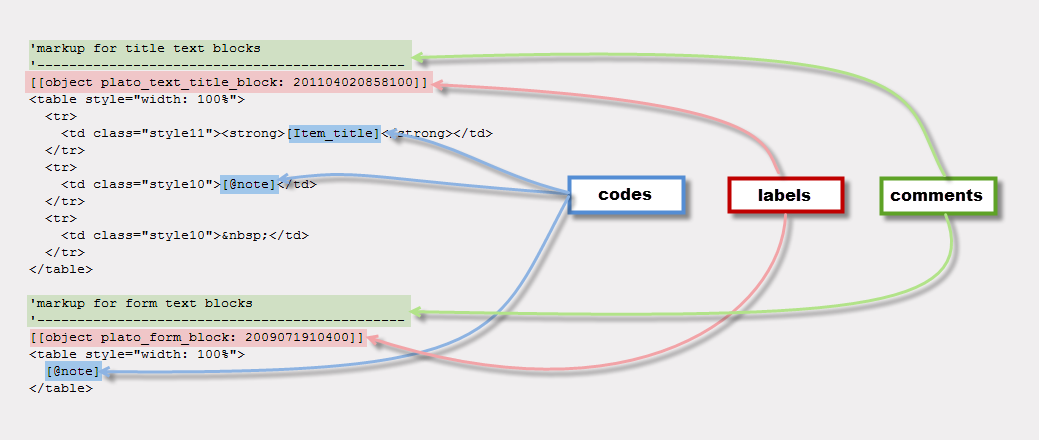
| Figure 1: Sample Markup Text Showing Labels and Codes |
|
Script markup is the means by which Plato data can be converted to documents. Script markup consists of text into which Plato data codes have been inserted. When the markup is processed by a script, the codes are substitued with actual data from Plato objects, similar to the way mail-merge works in a word processor. Plato codes are simply object attribute names in brackets, such as: [title]. Plato's markup editor allows you to insert Plato codes from a menu.
Script markup is also sectioned by labels. Labeled sections allow different snips of markup to be addressed to different object classes. the also allow the inclusion of post-processing instructions and swap lists. Labels are Plato assigned section titles enclosed in double brackets, such as [[head]]. Plato's markup editor allows you to insert labels from a menu.
Besides codes and labels, markup should simply conform to its use. If the output is to be plain text, then the markup should be formatted within the editor exactly the way you want it to appear in the output file. If the output is to be HTML, RTF, SGML, or some other markup language, the markup should conform to the rules of whatever language is to be used. When using a defined markup language, it's also best to first design a template that looks the way you want and then break up the template into the respective markup sections and insert the labels and codes.
Lines of markup that begin with an apostrophe (') will be treated as comments and ignored by Plato when it processes the markup.
Figure 1 shows an example of some HTML markup with labels, codes, and comments embedded in it.
Markup Examples
Here are a few examples to give you a better idea of how markup works (all are plain text examples).
This markup:
[author], [title], [publisher] ([date]).
Will result in:
John Steinbeck, The Grapes of Wrath, Random House (1946).
This markup:
Author:[author]
Title: [title]
Publisher: [publisher]
Date: [date]
Will result in:
Author:John Steinbeck
Title: The Grapes of Wrath
Publisher: Random House
Date: 1946
This markup:
[author/17] [title/25] [date]
Will result in:
John Steinbeck The Grapes of Wrath 1946
Note and field markup can be combined in a template as follows:
This markup:
[author], [title], [publisher] ([date]).
----------------------------------------------
Synopsis:
{note/wrap 2 74}
Will result in:
John Steinbeck, The Grapes of Wrath, Random House (1946).
----------------------------------------------
Synopsis:
The narrative begins just after Tom Joad is paroled from
McAlester prison for homicide. On his journey to his home
near Sallisaw, Oklahoma, Tom meets former preacher Jim Casy,
whom he remembers from his childhood, and the two travel
together. When they arrive at Tom's childhood farm home,
they find it deserted. Disconcerted and confused, Tom and
Casy meet their old neighbor, Muley Graves, who tells them
the family has gone to stay at Uncle John Joad's home
nearby. Graves goes on to tell them that the banks have
evicted all the farmers off their land, but he refuses to
leave the area.(Wikipedia)
|
|
| Using the Markup Editor for Script Markup |
|
|
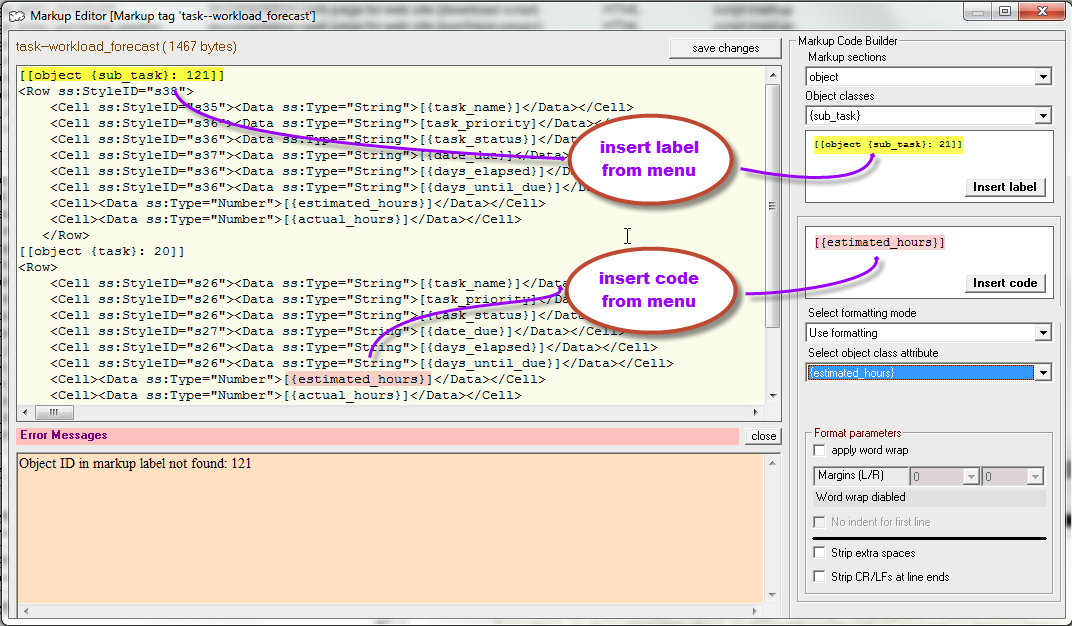
| Figure 2: Using the Markup Edit Pane and Markup Editor |
|
Figure 2 shows the markup editor configured for script markup. Note the editor pane is divided into two sections:- The Markup Editor The markup editor occupies the left side of the pane. At the top is the title of the markup being edited and a "save changes" button. Below this is the text window that holds the markup. You may enter or cut and paste text here just as you would in any text editor. Note that when you press the "save changes" button, Plato checks the markup text for errors. If errors are discovered, the error pane opens up below the text pane and displays a list of the errors along with their locations in the markup. Until the errors are corrected you won't be allowed to save the markup. Note that most errors can be avoided by using the markup code builder to generate markup codes and labels.
- The Markup Code Builder This is the set of controls to the right of the text window. Using these controls, you can automatically generate markup labels and codes, as well as macros and interal variables for insertion in the text. Figure 2 shows how codes and labels are inserted intop the markup.
Note that the markup editor controls are keyed to the selected section type: as you change the section type, the available controls will change based on the section you're selected. In some cases the editor will allow you to enter codes into a section using controls that are not applicable to it. However, the error checker will identify any inapplicable codes and force you to correct them before saving the markup.
The Markup Code Builder
The markup label builder consists of the following controls (top to bottom):
Markup Label Generator A dropdown list that allows you to select a markup section with which to generate a label. Below this is is a display of the label to be generated. Press the 'insert' button to insert the label at the current insertion point in the markup text. Labels consist of the section name enclosed in double brackets, such as: [[head]]. Sections allow you to assign different markup to different object classes. The following section labels may be used:Markup Code Generator Depending on the markup section chosen above, the code generator can be used to generate one of the following:- Plato attribute codes and formatting instructions Applies to sections labeled "object" and "bookmarks"
- Code Building Window Displays the code built using the code generator controls. Press the 'insert code' button to insert the code into the text editor.
- Select Object class Selects the object class for the label. The object class selected here will determine which attributes are displayed in the attribute drop down list.
- Select Object class attribute The attribute selected here will be displayed in the code building window.
- Select formatting mode This selection will determine what formatting, if any, will be applied to the attribute. This formatting is intended for plain text markup, and may have unpredictable effects if applied to markup for HTML, RTF, or other output.
- No formatting No formatting will be applied.
- Fixed length, no formatting The attribute will be displayed within a fixed-legnth area. The length of the area will be as specified in the 'length' drop down list. Fixed length formatting is intended to produce plain text column displays in which the columns are padded with spaces. Example:
[field name/20] = insert field contents in a fixed space of 20 characters - Use formatting Allows the attribute to be word wrapped and stripped of extra spaces and line ends. This is intended for large attributes such as notes but may be applied to any attribute. The formatting instructions produce the following codes:
- [note] insert contents of note
- [note/wrap 3 74] insert contents of note; word wrap into block starting at column 3 and ending at column 74
- [note/wrap 3 74 ni] same as word wrap command except the first line will start at column 0 (no indent)
- [note/strip space] insert contents of note and remove all extra spaces
- [note/strip returns] insert contents of note and remove all single CR/LF characters
These instructions may be combined: [note/wrap 2 74/strip space/strip returns]
- Macros and internal variables Applies to sections labeled "head," "tail," "post processing," and all swap list sections
- Macros Allows you to select a macro from the drop down list and insert it into the markup text. For more about macros, see below.
- Internal Variables Allows you to select an internal variable from the drop down list and insert it into the markup text. For more about internal variables, see below.
|
|
| Swap Lists |
Swap lists are a form of markup that allow you to substitute words, phrases, or characters during the course of script processing. The substitutions will show up in the output of the script but your original object data will be left unchanged.
Swap list syntax is fairly simple: One statement to a line; each line contains the text to be swapped, followed by an equal sign (=), followed by the replacement text. Use Plato macros for non-displaying characters and certain other characters (such as quotes) that may also be used as delimiters. When the text contains spaces (the literal space character, ASCII 32) enclose the text with quotes.
Swap lists are often necessary if your goal is keep your object data independent from markup. For example, you probably use quotation marks in your text where necessary. But if you use TeX or LateX as your document formatter, it will require that quotations be rendered `` and '' (left and right respectively). Changing your object data to conform to this convention will make it dependent on TeX/LateX, because other formatters may not recognize the TeX convention as quotes. The solution is to keep your quotes as they are but write a swap list to make conversions when TeX/LaTeX output is required.
Here's sample markup from a swap list addressing TeX/LateX quotes (the words starting with an ampersand are Plato macros):
&end_of_line"e = &end_of_line``
" \"e"= " ``"
"\"e "= "'' "
\"e&end_of_line = ''&end_of_line
Note that these swap list entries are having to account for quotes before and after the word, since in plain text theere is no distinction between a left and right quote, but in TeX there is.
Similarly, you probably press ENTER at the end of a line or paragraph (which puts a carriage return/line feed combination in your text file. But if you want to create RTF markup for use in word processors, carriage return/line feeds are ignored by RTF, which uses other line/paragraph markup conventions. Again, a swap list will resolve the problem and deliver good RTF markup without changing your object data.
Here's a sample line from a swap list addressing RTF paragraph breaks:
&end_of_para = \par}{\Pard
Swaps lists are not a universal solution to these sorts of problems but with a little ingenuity they can go a long way.
Remember that there are six swap list sections that may be used:- [[swap_list_markup]] Acts only on the markup before any object data is attached. This use is rather specialized and exists to allow you to swap in Plato reserved characters. For instance, if you markup has the text [balloon] in it, Plato will interpret it as an object attribute, and if it does not find a matching arrtribute in the selected object class it will flag the text as an error. Some entries in the SWAP-LIST-MARKUP section will fix this: in the markup type !balloon? and under the [[swap_list_markup]] section include the following two entries:
! = <
? = > - [[swap_list_metadata_only]] Acts only on object field data (metadata) before it is attached to markup.
- [[swap_list_notes_before/without_formatting]] Acts on notes without formatting, or (for notes with formatting instructions attached) before they are formatted.
- [[swap_list_notes_after_formatting]] For notes with formatting instructions, acts on the note after it has been formatted. For notes without formatting instructions, this has the same effect as 'swap list (notes before/without formatting).' Be careful--if you apply both swap list types to an unformatted note the results may be unpredictable.
- [[swap_list_markup_metadata_notes]] Acts on both object field data and notes after markup has been applied to them. This is the swap list type you will probably most often use.
- [[swap_list_bookmark_notes_only]] Acts only on the note field for bookmark objects (this allows footnotes or endnotes to have different formatting markup).
|
|
| Macros |
Macros are special keywords that Plato converts, or 'expands' into characters or series of characters. The may be used in markup and in other Plato data input fields.
|
|
| Macros for Character Substitution |
| These macros are typically used to insert characters into your script output that are 1) difficult or impossible to enter from the keyboard, or 2) don't display well and so make your markup instructions difficult to read. |
|
|
&CR |
ascii carriage return This is the ASCII control character for a carriage return (ASCII 13). In DOS and Windows text convention, the carriage return and the line feed (ASCII 10) character combine to form and end-of-line code. |
|
&LF |
ascii line feed This is the ASCII control character for a line feed (ASCII 10). In DOS and Windows text convention, the line feed and carriage return (ASCII 13) character combine to form an end-of-line code. In UNIX, the end-of-line code is represented by the line feed alone.
|
|
&end_of_file |
ascii EOF char This is the ASCII end-of-file character. This was a DOS convention, and was also used to designate file breaks in terminal input. |
|
&page |
form feed char This is the ASCII form-feed character. This was the DOS convention for a page break, but it is sometimes still found in text files.
|
|
&null |
ascii null This is the ASCII null character (ASCII 0). |
|
&tab |
tab char This is the ASCII tab character (ASCII 9). This character is still commonly found in text files and is typically expanded to the number of spaces specified by the text editor handing the file.
|
|
&space |
space This is the ASCII space character (ASCII 32).
|
|
&comma |
comma This is the ASCII comma character (ASCII 44).
|
|
"e |
quote This is the ASCII quote character (ASCII 34).
|
|
&end_of_line |
hard line end This expands to the ASCII carriage return and line feed characters (ASCII 13 and 10), and is commonly used to designate the end of a line in Windows text environments.
|
|
&end_of_para |
paragraph end This expands to two consecutive ASCII carriage return and line feed characters (ASCII 13 and 10), and is commonly used to designate the end of a paragraph in the Windows text environments. |
|
"es |
pair of quotes Expands to a pair of quotes (ASCII 34). |
|
&empty |
empty set Identifies any field or block of text that is empty of content.
|
| Macros for Stripping Characters from Input |
| These macros are typically used to strip unwanted characters from external data you are importing into Plato. For this reason they are mostly used in object import markup. |
|
|
&control |
any ascii control chars Expands to the complete set of ASCII control character (ASCII 0 through 31). |
|
&normal |
any ascii normal chars Expands to the set of "normal" ASCII characters: upper and lower case alpha (a-z, A-Z), numeric (0-9), and punctuation characters (ASCII 32 through 126). |
|
&extended |
any extended ascii chars Expands to the ASCII extended character set (ASCII 127-255). |
|
&numeric |
any ascii numeric chars Expands to the ASCII numeric characters 0-9 (ASCII 48-57).
|
|
&alpha |
any ascii alpha chars Expands to the ASCII alpha characters a-z and A-Z (ASCII 65-90 and 97-122).
|
|
&punctuation |
any ascii punctuation Expands to the ASCII punctuation characters ( !"#$%&'()*+,-./:;<=>?@[\] _`{|}~), or ASCII 32-47, 58-64, 91-96, and 123-126.
|
|
&spaces |
strings of more than 1 spaces This doesn't expand, but rather identifies any occurances of 2 or more consecutive spaces embedded in text. |
|
&extraCRLFs |
more than 3 CRLFs in a row This doesn't expand, but rather identifies any occuracnes of more than two carriage return/line feed combinations (ASCII 13 and 10) embedded in text. |
|
&garbage |
garbage characters Expands to a set of "garbage" characters commonly found in text (null, line feed, and carriage return--ASCII 00, 10, and 13).
|
|
&label_brackets |
label bracket characters Expands to a set of character pairs commonly used as brackets-- (), <>, [], and {} (ASCII 40,41; 60,62; 91,93; 123,125) |
| Macros for Find and Replace |
| These macros are typically used to describe characters to find or replace in find/replace scripts. Two special macros only have use in find/replace scripts: &any and &empty. For example, "find &empty" will locate fields that are empty; "find &any" will locate fields that have any content. |
|
|
&CR |
ascii carriage return This is the ASCII control character for a carriage return (ASCII 13). In DOS and Windows text convention, the carriage return and the line feed (ASCII 10) character combine to form and end-of-line code. |
|
&LF |
ascii line feed This is the ASCII control character for a line feed (ASCII 10). In DOS and Windows text convention, the line feed and carriage return (ASCII 13) character combine to form an end-of-line code. In UNIX, the end-of-line code is represented by the line feed alone.
|
|
&page |
form feed char This is the ASCII form-feed character. This was the DOS convention for a page break, but it is sometimes still found in text files.
|
|
&null |
ascii null This is the ASCII null character (ASCII 0). |
|
&tab |
tab char This is the ASCII tab character (ASCII 9). This character is still commonly found in text files and is typically expanded to the number of spaces specified by the text editor handing the file.
|
|
&space |
space This is the ASCII space character (ASCII 32).
|
|
&comma |
comma This is the ASCII comma character (ASCII 44).
|
|
"e |
quote This is the ASCII quote character (ASCII 34).
|
|
&empty |
empty set Identifies any field or block of text that is empty of content.
|
|
&any |
any character--like the wildcard * Identifies any field or block of text that isn't empty. |
|